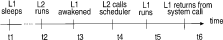
|
|
Designers of some fixed priority applications must have information on software latencies to analyze the performance characteristics of their applications and to predict whether performance constraints can be met. These latencies depend on kernel implementation and on system hardware, so it is not practical to list the latencies. It is useful, however, to describe some of the most important latencies. Consider the following time-line:
L1 and L2 represent LWPs; t1 through t6 represent points in time. Suppose that L1 has a higher priority than all other active LWPs, including L2. L1 runs and does a system call that causes it to sleep at time t1, waiting for I/O. L2 runs. The I/O device interrupts, resulting in a wakeup at time t3 that makes L1 runnable. If L2 is running in user mode at time t3, it is preempted immediately and the interval (t4 - t3) is, for practical purposes, zero. If L2 is running in kernel mode at time t3, it is preempted as soon as it gets to a safe place for preemption, a point in kernel code where no spin locks are held and where the state of the current LWP (L2 in this example) may be saved and a different LWP run. Therefore, if L2 is running in kernel mode at time t3, the interval (t4 - t3) depends on how long the kernel code needs to run before getting to such a safe point. It is useful to know both a typical time to preemption and a maximum time to preemption; these times depend on kernel implementation and on hardware. Eventually, the scheduler runs (at time t4), finds that a higher-priority LWP L1 is runnable, and runs it. We refer to the interval (t5 - t4) as the software switch latency of the system. This latency is, for practical purposes, a constant; again, it is an implementation-dependent value. At time t6, L1 returns to the user program from the system call that put it to sleep at time t1. For simplicity, suppose that the program is getting only a few bytes of data from the I/O device. In this simple case, the interval (t6 - t5) consists primarily of the overhead of getting out of the system call. We refer to the interval (t6 - t3) as the software wakeup latency of the system; this is the interval from the I/O device interrupt until the user LWP returns to application level to deal with the interrupt (if it is the highest priority LWP). So the software wakeup latency is composed of a preemption latency, context-switch time, and a part of system call overhead. Of course, the latency increases as the system call asks for more data.
This discussion of latencies assumes that the text and data of the processes and LWPs are in primary memory. An application may have to use process locking to guarantee that its processes and LWPs do not get swapped or paged out of primary memory. See the discussion in the previous section.